Doit-on attendre la fin d'une syllabe pour accéder à l'information qu'elle contient ? Autrement dit, la syllabe est-elle une étape limitante (un "bottleneck'') dans la perception la parole ? En particulier, les phonèmes sont-ils " récupérés'' seulement après l'identification de la syllabe à laquelle ils appartiennent ? À l'appui de cette conception, [Segui, Dupoux MehlerSegui 1990] citent des corrélations entre la durée ou la complexité d'une syllabe et les temps de latences pour détecter un phonème qui la débute. Cependant, l'idée que le système perceptif doive attendre la fin de chaque syllabe pour transmettre l'information vers les niveaux supérieurs a été critiquée. D'une part, [Marslen-WilsonMarslen-Wilson1984] a présenté des données qui indiquent que les sujets peuvent décider qu'un stimulus est un non-mot avec un temps de décision constant à partir du phonème critique, (c'est à dire celui à partir duquel le stimulus ne peut plus être un mot). Le point important est que les temps de décision ne sont pas affectés par la position syllabique du phonème critique (début ou fin de syllabe). D'autre part, des sujets peuvent apparemment détecter un phonème avant d'atteindre la fin de la syllabe qui le contient [Norris CutlerNorris Cutler1988,DupouxDupoux1989]. Toutefois, ces résultats demeurent compatibles avec un modèle en cascade, où un premier niveau de détecteurs de syllabes fournit en continue des "degrés d'activation'' ; la détection de phonème pourrait alors s'effectuer par "conspiration'' syllabique [DupouxDupoux1993]. Une autre possibilité est que les sujets puissent répondre sur la base d'un code demi-syllabique [DupouxDupoux1993] : les expériences de Dupoux et de Norris et Cutler utilisaient uniquement des syllabes CVC, et montrent que les sujets peuvent "ignorer'' le coda de syllabe. Dans ce chapitre, nous nous demandons si de l'information partielle sur la consonne initiale d'une sylabe CV peut être identifiée avant que la syllabe CV entière soit reconnue.
Pour étudier ce problème, nous nous sommes inspirés d'un article intitulé "Discrete versus Continuous Stage Models of Human Information Processing: In Search of Partial Output'' [MillerMiller1982]. L'auteur propose un paradigme expérimental qui permet de tester si le sujet peut amorcer une réponse motrice sur la base d'une analyse partielle d'un stimulus. Ce paradigme se fonde sur le fait que deux réponses effectuées par le même bras peuvent être "préparées'' plus efficacement que deux réponses effectuées par des bras différents. Plus concrètement, si l'on connaît à l'avance le bras de réponse, alors on est plus rapide pour répondre (il y a un "amorçage'' de la réponse motrice). Jeff Miller a eu l'idée de regarder si les sujets sont plus rapides quand une information partielle contenue dans un stimulus prédit le bras de réponse plutôt que quand elle ne le prédit pas.
Les sujets devaient classifier quatre stimuli visuels (par exemple `BE', `BO', `ME', `MO') en utilisant l'index et le majeur de chaque main (un doigt est assigné à chaque stimulus). Dans les blocs expérimentaux, les stimuli qui partagent une information partielle sont attribués à la même main (p.ex.: `BE' et `BO', qui partagent la même consonne initiale, sont assignés à la main droite ; `ME' et `MO', à la main gauche). Dans les blocs contrôles, les stimuli assignés à chaque main sont complètement différents et ne partagent aucune information partielle (par ex.: `BE', `MO' sont assignés à la main droite, `ME', `BO' à la main gauche). Si l'information partielle est extraite du stimulus avant que celui-ci soit reconnu entièrement, alors on s'attend éventuellement à observer des temps de réaction plus rapides dans les blocs expérimentaux que dans les blocs contrôles.
Miller (1982) a effectivement observé un effet de préparation du bras pour différents ensembles de stimuli, et en particulier pour les stimuli visuels BE, BO, ME, MO (voir également Jeff Miller , 1983). Il considère cela comme une preuve que l'identité de la première lettre est disponible pour faciliter la réponse avant que le stimulus entier soit identifié. Évidemment, ce résultat pourrait ne pas paraître trop surprenant car les lettres forment des codes nettement distincts, et de plus, sont séparées spatialement. On pourrait également penser que tout type de similarité entre les stimuli assignés à une main peut être utilisé pour faciliter la réponse. C'est précisément parce que ce n'est pas le cas, c'est à dire parce que la similarité ne provoque pas toujours de facilitation, que la méthode de Jeff Miller nous a intéressée.
Dans une de ses expériences (Miller, 1982, exp. 4), les sujets
devaient classifier les lettres U, V, M, N. La question était de
savoir si la forme globale de la lettre pouvait amorcer la
réponse : U et V sont semblables entre-elles, et assez
différentes de M et N, qui sont elles-mêmes assez similaires
entre-elles. De fait, dans une tâche de comparaison, les temps de
réaction sont nettement plus élevés pour discriminer deux lettres
de formes globales similaires (p.ex. U et V) plutôt que deux
lettres dissimilaires (p.ex. M et U). L'interprétation classique
de ce résultat est que, quand les lettres sont globalement
différentes, le sujet peut répondre avant d'avoir identifié
précisément les lettres, sur la base de la forme globale. Cela
suppose que la forme globale est identifiée avant l'identité de
la lettre. Si tel était le cas, dans le paradigme de Jeff Miller,
on s'attend alors à ce que les sujets soient plus rapides quand
des lettres similaires plutôt que dissimilaires sont attribuées à
la même main : la forme globale pouvant prédire le bras de
réponse. Or cela n'est pas le cas. Jeff Miller interprète
l'absence de facilitation en proposant que la forme globale d'une
lettre n'est pas accessible au système de réponse avant que la
lettre elle-même soit complètement identifiée.![[*]](foot_motif.gif)
Pour rendre compte du fait qu'on observe une préparation de
réponse pour des stimuli comme (BE, BO) vs (ME, MO) mais pas pour
(U, V) vs (M, N), Jeff Miller propose "qu'un trait partiel d'un
stimulus visuel ne peut servir à amorcer la réponse que s'il peut
activer un code discret par lequel l'information peut être
transmise'' (Miller, 1992, p.293). La
notion de "code discret'' est fondamentale, voilà plus
précisément ce qu'entend Jeff Miller par "code'' :
"It appears that the discrete versus continuous distinction reduces to a debate about the size of the unit of information transmission (i.e. the "grain size'' of information transmission). Continuous models state or imply that the grain size is effectively zero, so that any available information immediately begin to prime responses (cf., McClelland, 1979). Discrete models, on the other hand, must claim that information is transmitted discretely with respect to some information-rich internal "codes,'' perhaps of the type often studied within information processing psychology (e.g. Posner & Taylor, 1969). In these models, the grain size is considerably larger than zero, though it does not necessarily encompass all of the information in the whole stimulus.The notion of "code'' required here is closely related to that of [PosnerPosner1978], who said that "by a code I mean a format by which the information is represented'' (p.27). The idea is that the system may represent a stimulus in terms of several internal codes (e.g. letter identity and size). Each code could be processed discretely in the sense that no partial information about the code is ever made available to later processes. Yet response preparation could begin as soon as any code was completely activated, without waiting for full recognition of the other relevant codes. This model is refered to as the asynchronous discrete coding (ADC) model, since each code is transmitted discretely but different codes may be transmitted at different times'' (Miller, 1982, p.292).
Jeff Miller a employé exclusivement des stimuli visuels. Mais il nous a semblé que sa méthode était bien adaptée pour déterminer si des codes partiels, en particulier un code phonémique, peuvent être activés quand les sujets doivent reconnaître une syllabe présentée dans la modalité auditive. Dans un modèle de syllabaire où aucune information partielle n'est accessible au système de décision avant que la syllabe ne soit identifiée, on ne devrait pas observer d'effet de préparation de réponse. Si, par contre, le système de décision accède à l'information perceptive de façon continue, ou par "paquets'' plus petits que la syllabe elle-même, alors on peut s'attendre à observer un effet de préparation de la réponse. Dans l'expérience qui suit, nous avons demandé à des sujets de classifier quatre syllabes qui partageaient ou non la première consonne (FA, FU, SA, SU). Si celle-ci pouvait être identifiée avant la syllabe, alors on prédit un effet de préparation de réponse.
Cette expérience est similaire à la "BE BO ME MO'' de Jeff
Miller décrite plus haut, sauf que les stimuli étaient auditifs
(FA FU SA SU). Pour des raisons pratiques (possibilité de tester
de nombreux sujets), nous l'avons réalisée en Espagne, dans le
laboratoire de N. Sebastian-Gallès à l'Université de
Barcelone.
Une locutrice espagnole a enregistré deux exemplaires de chacune
des syllabes FA, FU, SA et SU. Nous avons ensuite enregistré sur
une bande magnétique une liste quasi-aléatoire de 200 stimuli
avec un intervalle entre deux stimuli qui était de 5 sec en début
de bande, 4.5 sec à partir du 15ième essai, 4 sec à partir du
30ième essai et 3.5 secondes à partir du 60ième essai (le rythme
s'accélérerait). La liste était "quasi-aléatoire'' car nous
avons fait en sorte que deux syllabes successives soit toujours
différentes. Sur la deuxième piste de
la bande, des clics inaudibles ont été placés au début de chaque
stimulus. La bande magnétique a été dupliquée en 5 exemplaires.
Le sujet était assis en face d'un PC (IBM PS/2) relié à un lecteur de cassette (TASCAM Porta One) et écoutait les stimuli à travers un casque. Après qu'il ait lu les instructions affichées sur l'écran de l'ordinateur, un bloc d'essais débutait. A chaque essai (démarré par le clic placé sur la piste 2 de la bande magnétique), le sujet entendait l'une des quatre syllabes FA, FU, SA, ou SU et devait appuyer sur l'une des quatre touches Z, X, N ou M pour classer la syllabe entendue. Le clavier espagnol est semblable au clavier américain : ces touches sont sur la dernière rangée, à gauche pour Z et X, et à droite pour N et M. Le sujet pressait respectivement, Z et X avec le majeur et l'index de la main gauche, N et M avec l'index et le majeur de la main droite. L'appariement des syllabes aux touches dépendait de la condition expérimentale du bloc (voir plus bas). L'ordinateur enregistrait la touche appuyée et le temps de réponse. Les sujets avaient deux secondes pour répondre.
Il y avait deux phases à chaque bloc d'essais : une phase d'apprentissage et une phase de test. Durant la phase d'apprentissage, le sujet voyait affiché en permanence sur la première ligne de l'écran, l'assignement des syllabes aux touches. Par exemple :
Z X N M
FA FU SA SU
De plus, à chaque essai, le sujet recevait une information sur sa réponse : selon que celle-ci était correcte ou pas, `Bien' ou 'Mal' s'affichait à l'écran. En cas de mauvaise réponse, la touche correcte (sur laquelle le sujet aurait du appuyer) clignotait à l'écran. Quand la différence entre le nombre de réponses correctes et le nombre de réponses erronées atteignait vingt-cinq, l'ordinateur basculait dans la phase de test. Dans cette phase, l'écran restait vide, sauf quand le sujet commettait une erreur, auquel cas la touche correcte clignotait pendant une seconde. La phase de test, contrairement à la phase d'apprentissage, avait une longueur fixe de 100 essais. Le bloc finissait avec cette phase. Tous les sujets ont atteint le critère d'apprentissage avant le centième essai, ce qui fait qu'aucun n'a atteint la fin de la liste de 200 stimuli durant la phase de test.
Nous avons employé un dessin intra-sujet dans lequel chaque sujet passait deux blocs : un bloc expérimental (avec, par exemple, FA et FU assignés à une main et SA et SU à une autre) et un bloc contrôle (avec, par exemple, FA et SU assignés à une main et SA et FU à l'autre). La même bande magnétique était employée pour tous les blocs, seul changeait l'assignement des touches. Les sujets se reposaient environ 5 minutes entre les deux blocs et l'expérience totale durait environ 25 minutes. L'ordre des blocs était contrebalancé, de telle façon que la moitié des sujets débutait par le bloc contrôle et l'autre moitié par le bloc expérimental. Finalement, cinq appariements syllabes-touches différents ont été employés pour faire varier les mains et les doigts associés à une syllabe particulière. Les sujets étaient testés par groupe de cinq et pour des raisons matérielles il était plus facile de n'avoir que cinq appariements. Les positions des syllabes n'étaient donc pas parfaitement contrebalancées. Les cinq appariements utilisés sont affichés dans la table 5.1.
30 étudiants de l'université de Barcelone, de langue maternelle espagnole et, pour la plupart, bilingues espagnol/catalan, ont participé à cette expérience en échange de points nécessaires à la validation de leur cursus. Ils étaient testés par groupes de quatre ou cinq, chacun dans un box isolé. Deux sujets supplémentaires ont été éliminés pour avoir fait plus de 20 % d'erreurs.
Nous avons effectué deux Analyses de Variance (a) sur les temps de décision moyens et (b) sur les taux d'erreurs (appuis sur une mauvaise touche). Deux facteurs étaient déclarés : la Condition : bloc expérimental ou bloc contrôle (intra-sujets), et l'Ordre de passation des blocs : contrôle puis expérimental ou l'inverse (facteur entre-sujets). La table 5.2 fournit les résultats moyens (sans distinguer l'"Ordre'').
| Contrôle | Expérimental | Différence | |
| fa su - fu sa | fa fu -sa su | ||
| TR Moyen | 807 ms | 754 ms | 53 ms |
| Erreurs | 9.6 % | 6.9 % | 2.7 % |
Voici les résultats des Anovas :
PLAN S15<O2>*C2 C = Condition (Bloc Exp\'erimental vs Contr\^ole) O = Ordre (1er bloc Exp\'erimental ou Contr\^ole) Temps de r\'eaction C F(1,28)= 10.48 MSE=3979.78 p=0.0031 O F(1,28)= 0.55 MSE=22568.6 p=0.4645 O.C F(1,28)= 0.92 MSE=3979.78 p=0.3457 Erreurs C F(1,28)= 11.27 MSE=9.2262 p=0.0023 O F(1,28)= 1.71 MSE=23.383 p=0.2016 O.C F(1,28)= 0.02 MSE=9.2262 p=0.1115
Dans l'analyse des erreurs comme dans l'analyse des temps de réaction, seul le facteur Condition produit un effet significatif. Il n'interagit pas avec le facteur Ordre. En sus de ces Anovas, nous avons examiné le nombre d'essais de la phase d'entraînement pour déterminer si l'appariement était plus difficile à apprendre dans les blocs expérimentaux que contrôles : en fait les nombres d'essais moyens sont de 30.8 et 30.7 respectivement et cette différence est non significative dans un t-test.
Les résultats sont clairs : quand la consonne initiale prédit le bras de réponse, les sujets sont plus rapides et commettent moins d'erreurs que lorsque les syllabes assignées à la même main ne partage aucun phonème. Il semble donc qu'on doive conclure que les sujets ont eu accès à un code sub-syllabique pour amorcer leur réponse.
Si l'on examine une représentation de l'acoustique des
stimuli, on observe deux segments successifs : un premier qui
contient un "bruit'' correspondant à la consonne fricative, et
un second, périodique, qui spécifie la voyelle. Le bruit fricatif
est très similaire à l'intérieur des couples (fa,fu) et (sa,
su). L'interprétation "à la Jeff Miller'' est que les
sujets ont pu utiliser ce premier segment acoustique pour
préparer le bras de réponse, en activant un code sub-syllabique.
Notons que ce code sub-syllabique n'est pas nécessairement un
phonème, ce pourrait tout aussi bien être un trait phonétique.
Une remarque, cependant, vient tempérer cette interprétation : la
tâche est assez difficile puisque les réponses sont effectuées
assez largement après la fin des stimulus (dont la durée moyenne
était de 410 msec pour un temps de réaction moyen de 800
msec). On peut donc se
demander si l'interprétation selon laquelle la différence de
temps de réaction reflète un traitement perceptif précoce de la
consonne, est correcte. Il semble possible que la syllabe soit
d'abord identifiée globalement, et que le code phonémique ne soit
récupéré qu'après coup. L'effet serait alors entièrement dû à
l'étape décisionnelle de "branchement'' de la réponse : le
code phonémique "faciliterait'' la réponse plutôt qu'il ne la
"préparerait''. Nous référerons à cette deuxième hypothèse
comme "hypothèse décisionnelle''.
Différencier une activation d'un code phonémique " pré-syllabique'' et "post-syllabique'' est très délicat. Mais si l'effet de préparation a pour origine une identification "en temps réel'' de la première consonne, alors il devrait être influencé par la distribution temporelle de l'information acoustique dans le signal. En particulier, on prédit qu'il ne devrait pas y avoir d'effet d'amorçage quand cette information vient seulement quand la syllabe peut déjà être identifiée. Une telle situation peut être créee en assignant à chaque main des syllabes partageant la même voyelle. En effet quand le sujet atteint l'information vocalique, la syllabe, aussi bien que la voyelle peut être identifiée ; il n'y alors pas de raison d'observer un effet de préparation (car il est "trop tard'' pour se préparer). Par contre, dans l'hypothèse d'une facilitation "post-syllabique'', la distribution temporelle de la consonne ou de la voyelle importe peu : on s'attend à ce que le code spécifiant la voyelle puisse "faciliter'' la réponse tout autant que le code consonantique le faisait dans cette expérience.
On a réalisé une expérience similaire à la précédente, mais cette fois-ci, dans le bloc expérimental, les syllabes partageaient la voyelle et non la consonne (fa,sa - fu,su). Si l'effet de préparation est dû à une activation en "temps réel'' du code phonémique (hypothèse "perceptive''), alors la distribution temporelle de l'information dans le signal détermine l'importance de la préparation, et les réponses ne devraient pas être amorçées par l'information vocalique (cf discussion précédente). Si, au contraire, l'interprétation "décisionnelle'' est correcte, alors la voyelle devrait "faciliter'' la réponse tout autant que la consonne dans l'expérience précédente.
La même bande magnétique que précédemment a été employée. La
procédure était identique à celle de l'expérience précedente.
Seul l'assignement des touches à été modifié, en échangeant
fa et su. Ainsi, dans les blocs expérimentaux, les syllabes
associées à la même main avaient la même voyelle (p.ex. FA SA - FU
SU). Les sujets, au nombre de 30, n'avaient pas participé à l'expérience précédente.
Cinq ont été éliminés et remplacés pour avoir fait
plus de 20 % d'erreurs.
Les données, résumées dans la table 5.3, ont été analysées comme dans l'expérience précédente.
| Contrôle | Expérimental | Différence | |
| fa su - fu sa | fa sa - fu su | ||
| TR Moyen | 842 ms | 771 ms | 71 ms |
| Erreurs | 10.1 % | 6.1 % | 4 % |
PLAN S15<O2>*C2 C = Condition (Bloc Exp\'erimental vs Contr\^ole) O = Ordre (1er bloc Exp\'erimental ou Contr\^ole) Temps de R\'eaction C F(1,28)= 17.04 MSE=4362.36 p=0.0003 O F(1,28)= 1.22 MSE=24340.5 p=0.2788 O.C F(1,28)= 1.02 MSE=4362.36 p=0.3212 Erreurs C F(1,28)= 22.44 MSE=10.3405 p=0.0001 O F(1,28)= 3.12 MSE=27.6786 p=0.0882 O.C F(1,28)= 0.23 MSE=10.3405 p=0.3648
L'effet de Condition est significatif sur les erreurs ainsi que sur les temps de réaction. Le facteur d'Ordre n'interagit pas avec la Condition. D'autre part, les nombres d'essais d'entraînement étaient de 32.4 dans les blocs expérimentaux et de 29.4 dans les blocs contrôles, mais cette différence n'était pas significative (t(29)=1.6 ; p=.12).
Quand la voyelle prédit le bras de réponse, les sujets sont plus
rapides et commettent moins d'erreurs. La facilitation est
même supérieure à celle observée quand la consonne prédisait le
bras de réponse (cette différence n'est toutefois pas
significative). Selon la
discussion de l'expérience précédente, cela suggère que l'amorçage n'est pas dû à
la prise en compte en continue de l'information
disponible dans le signal mais plutôt à l'étape décisionnelle
qui, après que le stimulus ait été reconnu, effectue le
branchement stimulus-réponse.
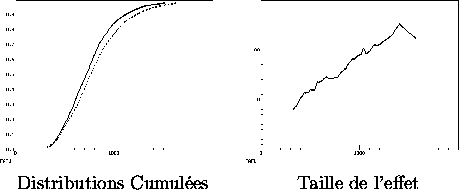
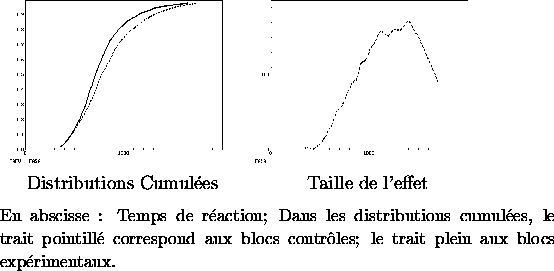
On peut se convaincre du caractère tardif de l'effet en traçant les distributions des temps de réaction bruts en fonction du type de bloc (expérimental ou contrôle). Sur les figures 5.1 et 5.2, on a affiché, à droite : les distributions cumulées de probabilité de réponses, et à gauche : la distance entre la distribution contrôle et la distribution expérimentale (selon une méthode de visualisation due à E. Dupoux). Le trait plein représente la distribution des réponses dans les blocs expérimentaux, le trait pointillé correspond aux blocs contrôles.
Comme on peut le constater la taille de l'effet augmente
avec le temps de décision Il devient dès lors paradoxal de considérer qu'un tel
effet reflète une "préparation''.
Nous avons décidé d'analyser les erreurs plus en détail, dans
cette expérience, ainsi que dans la précédente. Plus
particulièrement, nous voulions déterminer si les erreurs sont
plutôt de nature motrice (le sujet confondant les doigts de la
même main) ou plutôt de nature perceptive (il confondrait deux
stimuli similaires). Dans la table 5.4, nous indiquons le
nombre d'erreurs en fonction de la similarité entre la réponse et
le stimulus présenté, dans les deux expériences.
Dans la condition où les stimuli attribués à la même main
partagent la consonne (expérience FaFu, condition expérimentale),
les erreurs proviennent essentiellement du stimulus qui partage
la consonne (colonne `C'. p.ex., en entendant /fu/, le sujet
"appuie'' sur /fa/). Dans la condition où la voyelle signale la
main (exp. fAsA, cond. expér.), les erreurs proviennent
essentiellement du stimulus qui partage la voyelle (colonne `V'.
par ex. en entendant /fa/, le sujet appuie sur
/sa/). Par conséquent, dans les
blocs Tests des deux expériences, la confusion est plus
importante entre les stimuli qui sont assignés à la même main.
Cela est-il un effet "de main'' ou bien un effet de similarité
? Les conditions contrôles nous apportent la réponse : quand les
stimuli attribués à la même main ne partagent aucun phonème, il y
a très peu d'erreurs sur la même main (colonne ![]() ). Les
erreurs ne proviennent donc vraisemblablement pas d'une confusion
entre les doigts de la même main.
). Les
erreurs ne proviennent donc vraisemblablement pas d'une confusion
entre les doigts de la même main.
Un fait remarquable qui ressort de cette analyse est que, dans les situations contrôles, les stimuli confondus sont essentiellement ceux qui partagent la même consonne plutôt que ceux qui partagent la voyelle. Il y a donc, contrairement à ce que pourrait laisser penser la seule analyse des réponses correctes, une asymétrie entre les consonnes et les voyelles. Cela suggère que, dans les blocs contrôles, les erreurs puissent être des anticipations de réponse fondées sur la consonne, ce qui serait en contradiction avec notre interprétation décisionnelle et ferait pencher la balance en faveur de l'accès à de l'information partielle. Or, si l'on examine les temps de réaction sur les erreurs, on s'aperçoit qu'ils sont systématiquement plus lents que les temps de bonne réponse (quelle que soit la condition, Expérimentale ou Contrôle, et la similarité). Les erreurs ne sont donc pas des réponses particulièrement rapides. L'hypothèse qu'elles proviennent d'anticipation sur la base d'une information partielle ne semble pas confirmée.
En résumé, les erreurs ne sont pas dues à une confusion entre les doigts d'une main. Elles ne sont pas distribuées uniformément car il y a nettement moins d'erreurs entre des stimuli diffèrant à la fois par la voyelle et par la consonne, qu'entre ceux partageant un de ces deux phonèmes. Les confusions dépendent donc de la similarité entre les stimuli. Toutefois, cette similarité dépend de la condition expérimentale : en fonction de celle-ci l'attention semble être focalisée sur la consonne ou sur la voyelle. Dans le bloc expérimental de l'expérience "FaFu'', les sujets confondent plus les stimuli partageant la consonne, par exemple /fa/ et /fu/ plutôt que /sa/ et /su/. Dans le bloc expérimental de "FaSa'', c'est le contraire. Par défaut, dans les blocs contrôles, l'attention semble focalisée sur la consonne.
Nous avions choisi le paradigme de Jeff Miller car il semblait pouvoir révéler l'activation de codes transitoires issus de l'analyse partielle d'un stimulus. Plus précisement, dans notre cas, la question était de savoir si un code phonémique pouvait être identifié avant que la syllabe entière soit reconnue. Or, nous avons trouvé que l'effet d'amorçage moteur, indice selon Jeff Miller de l'activation précoce d'un code partiel, était également présent si l'information signalant ce code permettait également d'achever l'identification de la syllabe. Notre conclusion est que l'effet d'amorçage est en fait une facilitation décisionelle, mais ne reflète pas le décours temporel ("time-course'') des activations des codes phonèmiques et syllabiques.
Même si l'on rélègue l'effet de facilitation aux étapes décisionnelles, il faut néanmoins souligner qu'il implique l'existence d'un code infra-syllabique (structurellement sinon temporellement) ou, du moins, d'une relation de similarité entre syllabes qui fait que /fa/ et /fu/ sont plus proches entre-elles que /fa/ et /su/. À vrai dire, cela pourait ne paraître trop surprenant. En effet, il existe un code "phonémique'' tout trouvé qui est le code orthographique. Il y a peu de doute que nos sujets, étudiants de psychologie de première année, pouvaient parfaitement se représenter les quatre syllabes en utilisant les lettres : F, S, A , U. Il est plausible qu'après avoir perçu la syllabe, les sujets pouvaient employer une représentation orthographique de celle-ci, pour effectuer leur réponse. L'intérêt, pour eux, serait que l'"algorithme'' de branchement stimulus-doigt est plus facile à apprendre, retenir et/ou exécuter à partir du code orthographique qu'à partir d'un code syllabique. Bien sûr, on ne peut distinguer cette explication, d'une autre en terme de représentation phonémique.
Le rôle possible du code orthographique dans les tâches de
psycholinguistique ne doit pas être sous-estimé : ainsi, dans une
tâche de jugement de similarité, des enfants de 5 ans
(pré-scolaires), jugent plus similaires des syllabes globalement
semblables (/vis/ et /bez/) que des syllabes
qui ne partagent que le premier phonème (/bez/ et /bug/) ; par
contre, des adultes et des enfants sachant écrire, trouvent plus
similaires les syllabes qui partagent le même phonème initial
[Treiman BreauxTreiman
Breaux1982]. Ce résultat peut être
comparé à ce qu'a révélé notre analyse des erreurs : dans les
blocs contrôles, les syllabes les plus confondues possédaient
précisement la même consonne initiale.
Il serait passionnant de savoir si des sujets ne connaisant pas l'écriture alphabétique (enfants, illettrés, ou bien utilisateurs d'un système non alphabétique) montrent le même effet de facilitation. Nous n'avons malheureusement pas accès à de telles populations. Pour éliminer le recours au code orthographique, une autre possibilité est d'utiliser une relation de similarité qui ne transparaisse pas dans celui-ci ; c'est à dire d'utiliser des phonèmes similaires mais qui ne sont pas distingués nettement dans le système orthographique. Si l'on observe une facilitation, alors on saura qu'elle ne provient pas du code orthographique.
Nous désirons exploiter une relation de similarité qui ne soit pas
reflétée par un code orthographique, et même, si possible, par
aucun code conscient. Nous avons décidé d'employer les
trait phonétiques de voisement et de place, en utilisant des
syllabes se différenciant par des plosives initiales : /pa/,
/ta/, /ba/ et /da/. Nous comparons les cas où les syllabes
assignées à la même main partagent (a) le trait de voisement (pa
ta -- ba da) (b) le trait de place d'articulation (pa ba -- ta
da) (c) aucun trait (ba ta -- pa da). Il nous semble que la
plupart des sujets n'ont pas conscience des traits
distinctifs de voisement et de place. Par conséquent, si la
facilitation observée dans les expériences précédentes dépend de
l'existence d'un code conscient (en particulier
orthographique), on ne s'attend pas à
l'observer ici.
Un locuteur espagnol a enregistré un exemplaire de chaque syllabe /pa/, /ta/, /ba/, /da/. De façon similaire à l'expérience 5.1, on a construit une liste quasi-aléatoire formée de 200 stimuli que l'on a enregistrés sur une bande magnétique.
L'équipement et la procédure employés étaient identiques à ceux
des expériences précédentes. Il a suffit de modifier les
instructions en remplaçant /fa/, /fu/, /sa/, /su/ par /pa/, /ta/,
/ba/ et /da/ respectivement. Il y avait 4 conditions (cf
tab. 5.5) définies deux facteurs : (a) le trait (dit
"principal'') assigné à une main dans les blocs
expérimentaux : Voisement ou Place d'articulation et (b) la
congruence de l'index (le trait
"secondaire'' définit le type de doigt (index vs
majeur) ou non).
Chaque sujet passait dans l'une de ces conditions. La moitié d'entre eux débutaient par le bloc contrôle et l'autre moitié par le bloc expérimental. Il y avait donc 8 groupes de sujets.
Soixante-quatre sujets espagnols de l'université de Barcelone ont été testés, dans des conditions identiques à celles des expériences précédentes. Ces sujets étaient des étudiants de première année de psychologie qui n'avaient pas suivi de cours de phonétique. On a éliminé et remplacé 13 sujets supplémentaires qui avaient commis plus de 30 % d'erreurs dans un bloc.
Les temps de réaction moyens et les taux d'erreurs par sujets (cf
tab.5.6) ont été soumis à des ANOVAs à quatre facteurs
: un facteur intra-sujet : Condition (Expérimental vs Contrôle)
et trois facteurs entre-sujets : Trait (Voisement vs Place),
Index (Congruent ou Non-Congruent), Ordre (Nature du premier bloc
: Expérimental ou Contrôle). Ces Anova étant trop longues pour
figurer ici, elles sont détaillées en annexe (cf
p.![[*]](cross_ref_motif.gif) ). En résumé, il y a seulement deux effets
significatifs : (a) la Condition, les sujets étant 22 msec plus
rapides et faisant moins d'erreurs dans les blocs tests que dans
les blocs contrôles (TR : F(1,56)=6.48, p=.01; erreurs :
F(1,56)=7.61, p=.008) et (b) une interaction Condition
). En résumé, il y a seulement deux effets
significatifs : (a) la Condition, les sujets étant 22 msec plus
rapides et faisant moins d'erreurs dans les blocs tests que dans
les blocs contrôles (TR : F(1,56)=6.48, p=.01; erreurs :
F(1,56)=7.61, p=.008) et (b) une interaction Condition ![]() Ordre (TR : F(1,56)=8.77, p=.005 ; mais sur les erreurs
F(1,56)=1). Rapellons que le facteur Ordre désigne le type du
premier bloc (Expérimental ou Contrôle) ; cette interaction
reflète en fait une accélération de 25 msec entre le premier et
le second bloc dont le résultat est que la différence
Expérimental - Contrôle qui est de 48 msec chez les sujets qui
commencent par le bloc expérimental, devient nulle (-3.8 msec)
chez ceux qui commencent par le bloc contrôle. Dans l'analyse
canonique, les facteurs Trait et Index, ne produisent aucun effet
ou interaction significative. On a tout de même conduit des
analyses restreintes à chaque type de trait. Pour la Place
d'articulation, l'effet de Condition était significatif sur les
erreurs mais pas sur les temps de réaction (TR: 13 ms,
F(1,28)=1.37, p=.25; erreurs: 3.3 %, F(1,28)=5.19, p=.03). Pour
le voisement, c'était l'inverse : (TR: 30 ms, F(1,28)=5.58,
p=.03; erreurs: 2.8 %, F(1,28)=2.75, p=.11).
Ordre (TR : F(1,56)=8.77, p=.005 ; mais sur les erreurs
F(1,56)=1). Rapellons que le facteur Ordre désigne le type du
premier bloc (Expérimental ou Contrôle) ; cette interaction
reflète en fait une accélération de 25 msec entre le premier et
le second bloc dont le résultat est que la différence
Expérimental - Contrôle qui est de 48 msec chez les sujets qui
commencent par le bloc expérimental, devient nulle (-3.8 msec)
chez ceux qui commencent par le bloc contrôle. Dans l'analyse
canonique, les facteurs Trait et Index, ne produisent aucun effet
ou interaction significative. On a tout de même conduit des
analyses restreintes à chaque type de trait. Pour la Place
d'articulation, l'effet de Condition était significatif sur les
erreurs mais pas sur les temps de réaction (TR: 13 ms,
F(1,28)=1.37, p=.25; erreurs: 3.3 %, F(1,28)=5.19, p=.03). Pour
le voisement, c'était l'inverse : (TR: 30 ms, F(1,28)=5.58,
p=.03; erreurs: 2.8 %, F(1,28)=2.75, p=.11).
Globalement, les sujets sont plus lents et commettent plus d'erreurs quand ils ne peuvent pas prédire la main de réponse à partir d'un trait phonétique de la première consonne. L'effet de condition apparaît sur les erreurs pour la place d'articulation et sur les temps de réaction pour le voisement, mais l'absence d'interaction ne permet pas d'affirmer qu'il y a une différence entre les deux types de trait.
Ces résultats suggèrent que l'effet de facilitation observé avec cette tâche ne doit pas son existence à un code conscient. Toutefois, il faut noter que l'effet est nettement plus faible dans cette expérience que dans les deux précédentes. On ne peut donc exclure la possibilité qu'un code conscient, comme l'orthographe, accentue l'effet de facilitation.
Dans les expériences présentées dans ce chapitre, les sujets devaient classer quatre syllabes avec quatre doigts : l'index et le majeur des mains gauche et droite. Si la syllabe était " l'unité de perception primaire'', on aurait pu s'attendre à ce que les sujets effectuent un appariement direct entre le niveau syllabique et les doigts de réponse. Or, l'expérience 5.1 ("fafu'') a révélé que les réponses étaient plus faciles quand les stimuli assignés au même bras débutaient par la même consonne, plutôt que quand ils ne partageaient aucun phonème. Les sujets n'ont donc pas fondé leurs réponses sur un niveau purement syllabique, qui produirait un code quand une syllabe est identifiée. Ceci est d'autant plus remarquable que la tâche ne requérait explicitement que la manipulation de syllabes.
Si l'on accepte l'interprétation de Jeff Miller (1982), le résultat de l'expérience 5.1 montrerait que la consonne est identifiée avant la syllabe, et servirait à préparer la réponse motrice. Toutefois, étant donné que les temps de décision dépassent largement la durée des syllabes, ce résultat est également compatible avec une interprétation selon laquelle le code phonémique est récupéré après l'identification de la syllabe.
L'expérience 5.2 ("fasa'') suggère que cette seconde explication est probablement la plus correcte : on observe la même facilitation quand les syllabes attribuées à la même main partagent la voyelle. Or quand l'information vocalique est atteinte, la syllabe est reconnue, et donc il faut conclure que la voyelle "facilite'' la réponse plutôt qu'elle ne la " prépare''. Cette interprétation est renforcée par une analyse temporelle qui revèle que l'effet est présent essentiellement aux temps de réaction lents.
Nous nous sommes ensuite demandés si le code facilitateur pouvait être le code orthographique. L'expérience 5.4 (" pata''), montre que les sujets peuvent exploiter une similarité en termes de traits phonétiques de voisement et de place d'articulation pour faciliter leur réponse. Cela montre qu'un code non-orthographique, et même non-conscient (i.e. non manipulable explicitement), peut faciliter la réponse.
Dans les chapitres précédents, nous avions trouvé des effets syllabiques dans des tâches où les sujets devaient manipuler des phonèmes, ici nous observons des effets "sub-syllabiques'' dans une tâche où les sujets n'ont a priori qu'à manipuler des syllabes. Cette remarque prendra de l'importance dans le chapitre de conclusion. Dans le prochain et dernier chapitre expérimental, nous abandonnons les paradigmes de détection/classification de stimuli linguistiques (phonème ou syllabe) pour étudier l'influence des frontières syllabiques sur la détection de click.