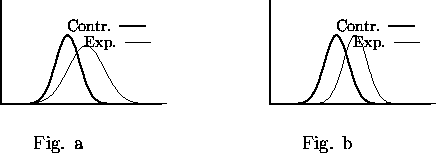Si les phonèmes sont perçus comme des unités indépendantes, alors
on peut s'attendre à ce que les sujets puissent focaliser leur
attention sur un phonème précis. Cette prédiction a été examinée
par [Wood DayWood Day1975] avec le paradigme d'interférence de
Garner![[*]](foot_motif.gif) : les sujets entendaient des listes de syllabes CV
dont ils devaient déterminer le plus rapidement possible la
consonne initiale (qui pouvait être soit b, soit
d). Dans certaines listes dites "simples'', la voyelle V
était unique : à chaque essai, le sujet entendait soit /ba/, soit
/da/. Dans d'autres listes, la voyelle pouvait varier d'un essai
à l'autre : le sujet entendait /ba/, /bæ/, /da/, ou /dæ/
(listes dites "variées''). Si la consonne est perçue
indépendamment de la voyelle, le sujet devrait pouvoir focaliser
son attention sur elle et la variation de la voyelle ne devrait
pas affecter son temps de décision. Au contraire, si la syllabe
est identifiée avant le phonème alors on peut s'attendre à
observer un ralentissement dans les listes "variées'' où il
faut reconnaître une syllabe parmi quatre par rapport aux listes
"simples'' où il faut reconnaître une syllabe parmi deux.
: les sujets entendaient des listes de syllabes CV
dont ils devaient déterminer le plus rapidement possible la
consonne initiale (qui pouvait être soit b, soit
d). Dans certaines listes dites "simples'', la voyelle V
était unique : à chaque essai, le sujet entendait soit /ba/, soit
/da/. Dans d'autres listes, la voyelle pouvait varier d'un essai
à l'autre : le sujet entendait /ba/, /bæ/, /da/, ou /dæ/
(listes dites "variées''). Si la consonne est perçue
indépendamment de la voyelle, le sujet devrait pouvoir focaliser
son attention sur elle et la variation de la voyelle ne devrait
pas affecter son temps de décision. Au contraire, si la syllabe
est identifiée avant le phonème alors on peut s'attendre à
observer un ralentissement dans les listes "variées'' où il
faut reconnaître une syllabe parmi quatre par rapport aux listes
"simples'' où il faut reconnaître une syllabe parmi deux.
[Wood DayWood Day1975] ont trouvé que les temps de réaction pour
classifier la consonne initiale étaient systématiquement ralentis
quand la voyelle variait, même lorsqu'on demandait
explicitement aux sujets d'ignorer celle-ci. Ils en ont
conclu que la perception ne se faisait pas phonème par phonème
mais que les sujets reconnaissaient d'abord la syllabe, puis
ensuite les phonèmes.
On pourrait penser que c'est le choix de plosives (/b/ et
/d/) à classifier, qui est responsable de ce résultat. En effet,
classiquement, les plosives sont considérées comme les phonèmes
les plus "encodés'', c'est à dire ceux dont la réalisation
acoustique varie le plus avec la voyelle qui les suit
[Liberman, Mattingly TurveyLiberman
1972]. Si le sujet se focalisait essentiellement sur
les aspects acoustiques du début des stimuli pour répondre, dans
les listes variées, il y aurait quatre "images acoustiques'' à
comparer aux stimuli, et seulement deux dans les listes simples.
L'effet de variabilité ne serait alors pas surprenant et
n'impliquerait pas un traitement global de la syllabe. Toutefois,
une remarquable étude de [Tomiak, Mullenix SawuschTomiak
1987] montre clairement que
l'explication du phénomène ne réside pas dans la variabilité
acoustique de la consonne : ils ont construit des syllabes
synthétiques (/fæ/, /![]() æ/, /fu/, /
æ/, /fu/, /![]() u/) en "
collant'' les fricatives aux voyelles de façon à ce qu'il n'y
ait aucune coarticulation entre les deux segments acoustiques. En
fait, le premier segment acoustique de 150 msec identifiait de
manière non ambiguë la fricative et ne contenait aucune
information sur la voyelle qui suivait. Pourtant la variation de
la voyelle affectait encore largement les temps de classification
de la consonne.
u/) en "
collant'' les fricatives aux voyelles de façon à ce qu'il n'y
ait aucune coarticulation entre les deux segments acoustiques. En
fait, le premier segment acoustique de 150 msec identifiait de
manière non ambiguë la fricative et ne contenait aucune
information sur la voyelle qui suivait. Pourtant la variation de
la voyelle affectait encore largement les temps de classification
de la consonne.
Ce résultat suggère que la perception "unitaire'' de la syllabe ne reflète pas purement la structure physique du stimulus mais est bien le résultat d'une intégration mentale (l'effet est "dans la tête'' des sujets). La suite de l'étude de [Tomiak, Mullenix SawuschTomiak 1987] le démontre encore plus clairement : les syllabes synthétiques étaient telles qu'il était possible de les entendre soit comme des syllabes, soit comme des "bruits''. À la moitié des sujets elles étaient effectivement décrites comme des syllabes, alors qu'à l'autre moitié elles étaient décrites comme du "bruit''. C'est seulement quand elles étaient considérées comme des sons langagiers que la variation produisait un ralentissement ! Les mêmes stimuli physiques sont traités différemment selon qu'ils sont perçus comme de la parole ou comme du "bruit''. À notre avis, une interprétation plausible de ces résultats est que, dans le mode "linguistique'', le modèle mental de la cible que se forment les sujets et qu'ils comparent à chaque essai au stimulus à classifier, doit nécessairement spécifier la voyelle ; il s'agirait donc d'une syllabe (ou au moins d'une demi-syllabe).
Deux autres études, utilisant la tâche de détection de phonème initial, nous semblent pouvoir être interprétées de la même façon : ce sont celles de [MillsMills1980] et [Swinney PratherSwinney Prather1980]. Chez [MillsMills1980], les sujets entendaient des listes de sept syllabes CV dans lesquelles ils devaient détecter un phonème en position initiale. Le phonème cible (/b/ ou /s/), était précisé en tête de chaque liste, de la façon suivante : " vous devez détecter /b/ comme dans /be/'', tandis que, dans la liste elle-même, il pouvait apparaître soit dans /bo/, soit dans /be/. [MillsMills1980] observe que les sujets sont plus rapides quand la syllable portant la cible correspond à celle de la consigne, et ceci, même quand on leur demande explicitement d'ignorer la voyelle. Cet effet suggère que le modèle de la cible que le sujet se forme pour effectuer la tâche est syllabique.
[Swinney PratherSwinney
Prather1980] obtiennent un résultat comparable avec une
méthode un peu différente. Ils utilisaient une tâche de détection
mixte (phonème ou syllabe) : chaque bloc expérimental consistait en
une série de petites listes de 5 à 12 monosyllabes CVC qui
pouvaient contenir la cible (un phonème ou une syllabe). Il y
avait trois blocs qui se différenciaient par la variabilité du
contexte vocalique où pouvait apparaître la cible : dans un bloc,
celle-ci était systématiquement suivie de la même voyelle ; dans
un autre la cible était suivie par une voyelle parmi quatre ; dans
le troisième bloc il y avait huit contextes vocaliques.
[Swinney PratherSwinney
Prather1980] ont observé que la variabilité ralentissait
les sujets.
En résumé, les études que nous venont de décrire montrent indubitablement que les sujets ne peuvent ignorer la voyelle qui suit une consonne sur laquelle ils doivent prendre une décision, et que ceci n'est probablement pas un effet acoustique de bas niveau. Une interprétation possible de ces résultats est que, conformément à un modèle syllabique (ou demi-bisyllabique) de la perception de la parole, les sujets identifient la syllabe CV en entier avant d'avoir accès à la consonne. Dans la condition non-variée, l'identification d'une syllabe parmi deux est suffisante pour décider de la réponse : il n'est pas nécessaire d'inspecter un code phonémique. On peut proposer deux causes du ralentissement dans la condition variée: (a) il faut identifier une syllabe parmi quatre, ou (b) il faut segmenter la syllabe en consonne-voyelle.
Cette interprétation n'est toutefois pas la seule qui puisse rendre compte de ces résultats. On peut proposer que les phonèmes sont extraits indépendamment les uns des autres mais que la variation d'un phonème adjacent ralentit la décision. Par exemple, [Eriksen EriksenEriksen Eriksen1974] ont montré que les sujets qui devaient identifier une lettre (présentée visuellement), étaient incapables d'ignorer des lettres voisines, a priori non pertinentes pour effectuer la tâche. Plus précisement, une lettre cible était présentée au-dessus d'un point de fixation, et le sujet devait décider de son identité (en appuyant sur un bouton pour H ou K, et sur un autre pour S ou C). À gauche et à droite de la cible, apparaissaient d'autres lettres plus ou moins semblables à celle-ci, que le sujet avait pour instruction d'ignorer. Pourtant, ces lettres ralentissaient la réponse quand elles étaient dissimilaires à la cible ou prédisaient une réponse incompatible. Cela montre que les sujets ne pouvaient focaliser entièrement leur attention sur la lettre cible : les lettres adjacentes étaient identifiées automatiquement et interféraient dans les processus de décision sans que les sujets puissent l'empêcher (un peu comme un effet "Stroop'').
On peut donc imaginer qu'il en est de même dans la modalité
auditive : lorsque le sujet entend une syllabe CV, les phonèmes
sont identifiés automatiquement, et leur variation gène
la décision. Cette idée, selon laquelle c'est l'étape de
décision qui est responsable du ralentisement observé entre les
blocs expérimentaux et contrôles dans le paradigme de Garner, a
été discutée par certains auteurs (p.ex. Miller, 1978,
p.179). Le contre-argument classique est qu'il
existe des cas où la variabilité ne provoque pas d'interférence.
Par exemple,
[WoodWood1974] a trouvé que les sujets n'étaient pas ralentis par
une variation phonétique quand ils devaient classifier des
syllabes (deux ou quatre) selon leur hauteur mélodique ("pitch
''). Cependant, dans les cas où l'on
n'a pas observé d'interférence, la dimension à classifier était
de nature différente de la dimension qui variait (par exemple,
une dimension acoustique et une dimension phonétique). Quand la
dimension à classer et la dimension qui varie appartiennent à un
même niveau de représentation (ce qui est le cas pour les
interférences entre phonèmes observées par Wood et Day), il se
pourrait que l'interprétation décisionnelle soit correcte.
Quoiqu'il en soit, si du fait qu'il est impossible de focaliser sélectivement l'attention sur un phonème, on veut déduire que ce dernier n'est pas l'unité perceptive, alors on ne peut accorder ce statut à la syllabe que si l'on montre que l'attention peut être sélectivement focalisée sur elle. Nous avons donc réalisé une expérience utilisant le paradigme de Garner, semblable à celle de [Wood DayWood Day1975], si ce n'est que les phonèmes étaient remplacés par des syllabes. Si l'on observe que les sujets peuvent classifier une syllabe sans être gênés par la variation dans une autre syllabe, alors la thèse "syllabe = unité perceptive'' aura gagné du crédit. Si, au contraire, on observe une interférence entre syllabes, il faudra alors supposer : soit que l'unité perceptive est plus grande que la syllabe, soit que l'interprétation décisionnelle avancée plus haut est correcte.
Dans cette expérience, nous examinons si l'attention peut être focalisée sélectivement sur la première syllabe de stimuli bisyllabiques CV-CV. Les sujets doivent classifier la première syllabe et ignorer la seconde. Dans les blocs expérimentaux, cette dernière varie alors que dans les blocs contrôles elle reste la même.
Un locuteur masculin a enregistré les quatre stimuli /paku/, /toku/, /pagi/ et /togi/. Avec ceux-ci, nous avons constitué quatre listes aléatoires comprenant chacune 64 items. Deux listes, dites "contrôles'', contenaient deux stimuli qui ne différaient que par la première syllabe (la première liste contenait 32 items /paku/ et 32 items /togu/; la seconde liste contenait 32 /pagi/ et 32 /togi/). Deux autres listes, dites " expérimentales'', contenaient les quatre stimuli (chacun en 16 exemplaires) ; elles ne différaient que par l'ordre (aléatoire) des items.
Chaque sujet était testé individuellement. L'expérience se
déroulait entièrement sous le contrôle d'un ordinateur portable,
le protocole expérimental étant décrit dans un langage de
description d'expérience développé par
l'auteur. Les stimuli, stockés sur le
disque dur du PC, étaient restitués au sujet par l'intermédiaire
d'un casque stéréophonique de haute fidélité AKG.
Au début de l'expérience, le sujet entendait une fois chacun des quatre stimuli. Puis, il lisait les instructions affichées sur l'écran de l'ordinateur. Celles-ci précisaient qu'il entendrait des listes formées avec ces stimuli, qu'il devrait "se concentrer sur la première syllabe de chaque <<mot>>'' et " appuyer sur le bouton de réponse droit pour /PA/ et gauche pour /TO/''. On lui demandait également de "de répondre le plus rapidement possible'' mais d'"éviter de commettre des erreurs''. Après lecture des instructions, le sujet effectuait un entraînement à la tâche, sur un bloc de 16 essais comprenant les quatre stimuli.
Chaque essai débutait par la présentation auditive d'un stimulus
et le sujet avait 1500 msec pour répondre. Puis, il voyait
s'afficher son temps de réaction si la réponse était correcte, ou
un rappel de l'assignation des cibles aux clés de réponse s'il
avait commis une erreur. L'intervalle entre chaque essai était de
3 secondes (augmenté de 800 msec en cas de mauvaise réponse). À
la suite de cet entraînement, la partie expérimentale proprement
dite commençait : chaque sujet entendait quatre blocs successifs
correspondant chacun à une des listes décrites dans la section
précédente. À l'intérieur de chaque bloc, les essais avaient
une structure identique à ceux du bloc d'entraînement (en
particulier, les sujets recevaient du "feed-back'' après
chaque essai).
Au début de chaque bloc, le sujet était autorisé à se détendre
pendant environ une minute ; les instructions étaient réaffichées
à l'écran et indiquaient quels stimuli allaient être présents
dans le bloc à venir tout en rapellant qu'il fallait se concenter
sur la première syllabe. Globalement, l'expérience durait environ
une vingtaine de minutes. L'ordre des listes était contrebalancé
entre les sujets comme indiqué sur la table
2.1.
| Sujets | 4|c|Séquence | |||
| 1-2 | C1 | E1 | C2 | E2 |
| 3-4 | E1 | C1 | E2 | C2 |
| 5-6 | C2 | E2 | C1 | E1 |
| 7-8 | E2 | C2 | E1 | C1 |
E1=liste exp. 1 ; E2=liste exp. 2
C1=cont.
(paku/toku) ; C2=cont. (pagi/togi)
Huit sujets étudiants de l'EPITA (une école d'ingénieurs en informatique située dans Paris XIII), d'âges compris entre 20 et 24 ans, de langue maternelle française et sans déficits avérés de l'audition, ont participé à cette expérience. Ils recevaient une rétribution de 20 FF pour leur participation.
On a éliminé systématiquement les huit premiers temps de réaction
de chaque bloc (considérés comme des "échauffements'') et on
a pris en compte uniquement les cinquante-six suivants. Puis on a
calculé, pour chaque sujet et dans chaque bloc, le taux d'erreurs
(comptabilisant les absences de réponse et les appuis sur la
mauvaise clé) et le temps de réaction moyen sur les réponses
correctes. Les moyennes sont
présentées dans la table 2.2.
Un simple t-test révèle que le ralentissement de 38 ms entre les blocs expérimentaux et les blocs contrôles est significatif (t(7)=4.5, p=.003). Par contre, la différence de taux d'erreurs n'est pas significative (t(7)=.3, p=.8). Dans un deuxième temps, nous avons conduit une Anova sur les temps moyens de réaction, en incluant, en plus du facteur << Expérimental >> (X) qui distingue les blocs expérimentaux et les blocs contrôles, deux autres facteurs :
L'Anova suivait un plan X2*O2*M2, les trois facteurs étant
déclarés intra-sujet. Le tableau d'anova est détaillé plus
bas. L'effet du facteur Expérimental est
significatif (conformément au t-test). Par contre, ni l'effet
d'Ordre (17 ms, F(1,7)=1.9, p=.2), ni l'effet de Moitié de bloc
(15 ms, F(1,7)=2.6, p=.15) n'atteignent la significativité. De
plus, ils n'interagissent pas avec l'effet Expérimental. Les
effets expérimentaux restreints respectivement à la première
moitié et à la seconde moitié des blocs s'avèrent significatifs
(X/M1 : 48 ms, F(1,7)=13.3, p=.008; X/M2 : 38 ms, F(1,7)=6.0,
p=.05). L'effet expérimental est significatif dans la seconde
moitié de l'expérience (pour les blocs 3-4 : X/O2 : 45 ms,
F(1,7)=5.9, p=.05) ; il ne l'est pas dans la première moitié
(X/O1 : 31 ms, F(1,7)=1.8, p=.22), mais cela résulte
vraisemblablement d'une plus grande variabilité (cf MSE). Une
anova similaire sur les erreurs ne révèle aucun effet
significatif.
Temps de r\'eaction : PLAN S8*M2*O2*X2
X = Exp\'erimental
O = Ordre (O1=blocs 1-2 et O2=blocs 3-4)
M = Moiti\'e de bloc (M1 = d\'ebut et M2 = fin)
X F(1,7)= 19.56 MSE=1192.28 p=0.0031
O F(1,7)= 1.85 MSE=2512.64 p=0.2160
O.X F(1,7)= 0.13 MSE=6028.32 p=0.2709
M F(1,7)= 2.57 MSE=1466.79 p=0.1529
M.X F(1,7)= 1.33 MSE=1262.68 p=0.2867
M.O F(1,7)= 0.95 MSE=401.013 p=0.3622
M.O.X F(1,7)= 0.01 MSE=755.376 p=0.0769
X/M1 F(1,7)= 13.30 MSE=1409.29 p=0.0082
X/M2 F(1,7)= 5.97 MSE=1045.67 p=0.0445
X/O1 F(1,7)= 1.76 MSE=4462.34 p=0.2263
X/O2 F(1,7)= 5.89 MSE=2758.27 p=0.0456
Les sujets sont plus lents pour décider quelle est la
première syllabe d'un stimulus CV-CV quand les blocs contenaient
/paku/,/toku/, /pagi/ et /togi/, que quand ils contenaient, soit
/paku/ et /toku/, soit /pagi/ et /togi/. Bien qu'on leur demande
de se concentrer sur la première syllabe, les sujets ne semblent
pas capables d'ignorer la variation de la seconde
syllabe. Cet effet ne semble pas diminuer avec
l'entraînement (entre les blocs ou à l'intérieur de chaque
bloc).
Nous avons proposé dans l'introduction qu'on pouvait interpréter l'effet d'interférence Garner sur le phonème initial (chez Wood & Day et Tomiak et al.) de deux manières : (a) en supposant que l'unité perceptive était plus grande que le phonème ou, (b) en attribuant l'effet à l'étape de décision dans ce type de tâche, qui ferait qu'on ne peut focaliser son attention sur l'"objet'' à classer quand un autre "objet'' varie sur la même surface de représentation. Avec l'effet d'interférence sur la syllabe que nous venons de dévoiler, les deux raisonnements peuvent encore être proposés : on peut dire (a) qu'il faut proposer une unité perceptive plus grande que la syllabe, ou bien (b) que c'est l'étape de décision qui est la principale responsable de l'interférence.
Toutefois, avant d'examiner cette alternative, il nous faut écarter une autre interprétation possible du résultat : on pourrait argumenter que les sujets arrivent effectivement à focaliser leur attention sur la première syllabe mais que c'est la variabilité acoustique de cette syllabe qui les ralentit. Par exemple, on sait que dans une tâche de comparaison ("matching''), le temps pour comparer deux syllabes est plus important si celles-ci sont physiquement différentes [Pisoni TashPisoni Tash1974]. Dans cette optique, il n'est même pas besoin d'invoquer la syllabe : on pourrait avancer que le sujet se forme des images acoustiques du début du signal pour chaque stimuli et compare celles-ci avec le stimulus présenté à chaque essai. Il y a alors deux images à comparer dans la condition contrôle et quatre dans la condition expérimentale, ce qui rendrait compte de l'effet. L'étude de Tomiak et al. citée plus haut a montré la limite des explications acoustiques dans la tâche "à la Garner''. Néanmoins, nous avons décidé de répliquer notre expérience en construisant des stimuli dont la première syllabe est physiquement identique à l'intérieur des paires (paku, pagi) et (toku, togi).
Class. de Syllabes
Elle était en tous points identique à la précédente.
Huit sujets étudiants, d'âges compris entre 23 et 27 ans, ont participé volontairement à cette expérience. Ils n'avaient pas participé à la précédente.
Les données ont été préparées comme dans l'expérience précédente. Les résultats moyens figurent dans la table 2.3.
Les t-tests révèlent que l'effet Expérimental est significatif sur les temps de réaction (47 ms, t(7)=3.8, p=.007), mais pas sur les erreurs (t(7)=.5, p=.6). Des Anovas similaires à celles de l'expérience précédente ont été conduites, sur les temps de réaction et les erreurs, avec les trois facteurs intra-sujet : Expérimental, Ordre et Moitié de bloc. Elles révèlent que seul l'effet Expérimental est significatif dans les temps de réaction. Les facteurs Ordre et Moitié ne produisent ni effet ni interaction significative.
Temps de r\'eaction
PLAN S8*M2*O2*T2\par
X = Exp\'erimental
O = Ordre
M = Moiti\'e de bloc (M1 = d\'ebut et M2 = fin)\par
X F(1,7)= 15.26 MSE=2335.09 p=0.0059
O F(1,7)= 2.97 MSE=6154.25 p=0.1285
O.X F(1,7)= 1.87 MSE=1317.9 p=0.2138
M F(1,7)= 0.06 MSE=1055.28 p=0.1865
M.X F(1,7)= 0.77 MSE=297.997 p=0.4093
M.O F(1,7)= 1.73 MSE=672.777 p=0.2299
M.O.X F(1,7)= 0.14 MSE=999 p=0.2806
X/M1 F(1,7)= 14.49 MSE=1434.16 p=0.0067
X/M2 F(1,7)= 12.57 MSE=1198.92 p=0.0094
X/O1 F(1,7)= 8.90 MSE=3193.48 p=0.0204
X/O2 F(1,7)= 21.07 MSE=459.516 p=0.0025
Une Anova supplémentaire rassemblant les données de cette
expérience et de la précédente et déclarant un facteur <<
Expérience >>, révèle que celui-ci ne produit aucune interaction
significative, et que la différence de temps moyen entre les deux
expériences (comparaison entre sujets) est marginale (63 ms,
F(1,14)=3.68, p=.08).
Dans cette analyse, le facteur Ordre devient significatif
(F(1,14)=5.02, p=.04), mais le facteur Moitié ne produit aucun
effet. Aucune interaction n'est significative dans cette analyse
et l'effet expérimental est significatif dans toutes les
restrictions (début ou fin d'expérience, début ou fin de bloc).
L'Anova détaillée se trouve en annexe (p.![[*]](cross_ref_motif.gif) ).
).
Comme dans l'expérience précédente, les sujets sont gênés par la variation de la seconde syllabe quand ils doivent classifier la première syllabe de stimuli CV-CV. Cette expérience-ci montre que l'effet ne peut pas s'expliquer par la variabilité acoustique de la première syllabe, puisque il n'y avait qu'un unique exemplaire physique de /pa/ et qu'un unique exemplaire physique de /to/ dans chaque liste.
On pourrait imaginer que, dans les blocs expérimentaux, il soit possible de focaliser quelquefois son attention sur la première syllabe mais pas dans tous les essais. Selon cette hypothèse, il y aurait deux types d'essais : ceux où l'attention est correctement engagée et où le sujet est rapide, et ceux où l'attention n'est pas correctement engagée et où le sujet est lent. La différence entre les blocs expérimentaux et contrôles devrait donc être due essentiellement aux temps de réaction lents. Si c'est le cas, on s'attend à ce que les distributions de probabilité des temps de réaction soient dans la relation indiquée sur la figure 2.1a. Si, au contraire, le ralentissement est global, les distributions devraient plutôt ressembler à la figure 2.1b.
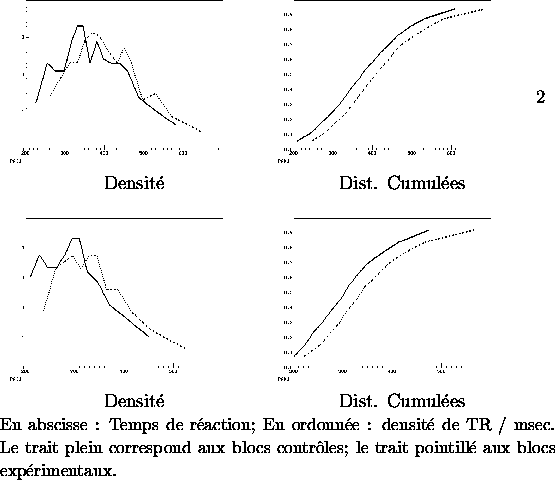
Nous avons donc tracé les distributions des temps de réaction bruts des blocs expérimentaux et contrôles des deux expériences (896 données par courbes). À gauche, on a indiqué la densité de probabilité des réponses en fonction du temps de réaction ; à droite, on a représenté la distribution cumulée correspondante, qui lisse les "accidents''.
Comme on peut le voir sur la figure 2.2, la situation dans les deux
expériences est plutôt celle de la fig.2.1b : la
distribution dans la condition expérimentale est décalée
globalement par rapport à la distribution dans la condition
contrôle. L'effet ne
provient pas uniquement des temps de décision lents : il est
présent sur les temps les plus rapides qui sont de l'ordre de 200
msec. Par conséquent, l'hypothèse que le ralentissement dans les
blocs expérimentaux serait dû à un échec attentionnel restreint
seulement aux essais les plus lents, peut être
écartée.
Le résultat principal des expériences 2.1 et 2.2 est que les sujets ne sont pas parvenus à focaliser leur attention sur la première syllabe des stimuli. L'expérience 2.2 montre qu'ils n'ont pas utilisé une représentation de l'acoustique du début des stimuli. Le caractère remarquable de ce dernier résultat mérite d'être souligné : depuis l'étude de [Pisoni TashPisoni Tash1974], où les sujets appariaient plus rapidement deux syllabes physiquement identiques que deux syllabes physiquement différentes, il est couramment admis que les sujets peuvent accéder à "de l'information acoustique de bas niveau en même temps qu'à une représentation phonétique plus abstraite'' (Pisoni et Tash 1974, p. 290; voir également, par exemple, [SamuelSamuel1977,MillerMiller1994]). On aurait pu s'attendre à ce que, comme un très faible nombre de stimuli est employé dans nos expériences, les sujets allaient pouvoir exploiter l'information acoustique de début de stimlus pour répondre. Ils ne l'ont apparemment pas fait (pas plus qu'ils ne pouvaient le faire dans l'étude de Tomiak et al., du moins en mode "parole'').
Pourquoi les sujets étaient-ils capables d'utiliser l'information acoustique dans l'étude de Pisoni et Tash mais pas dans la nôtre ? Une première remarque est que nos stimuli étaient bisyllabiques. On peut imaginer que la seconde syllabe masque rétroactivement la première et que les sujets ne pouvaient donc utiliser une représentation acoustique pour répondre. Cette hypothèse fait la prédiction intéressante que l'effet obtenu par Pisoni et Tash devrait disparaître si l'on demande à des sujets de comparer les syllabes initiales de stimuli multisyllabiques. Cependant, le masquage rétroactif ne peut expliquer l'interférence observée dans leurs expériences par [Tomiak, Mullenix SawuschTomiak 1987], qui utilisaient, eux, des monosyllabes.
Une seconde remarque est qu'il existe des cas où les sujets effectuent la tâche de comparaison sans, apparemment, utiliser de l'information de bas niveau. [ForsterForster1979] a proposé un modèle pour expliquer les faits suivants :
Forster (1979) propose de résoudre cette contradiction apparente
en "considérant comment la décision est effectuée : les objets
sont comparés, simultanément, à différents niveaux d'analyse. Quand
les formes sont assez simples (comme dans le cas des lettres
individuelles), la comparaison peut être réalisée rapidement au
niveau le plus bas des traits visuels, au point que les plus
hauts niveaux d'analyse ont peu de chance de fournir une réponse
avant ce niveau là. C'est donc le niveau des traits qui contrôle
la décision. Par contre, si les stimuli sont plus complexes
(p.ex. des mots), la comparaison au niveau des traits visuels
devient vraisemblablement trop lente (car il y a de nombreux
traits à comparer), au point que la réponse peut alors provenir
des hauts niveaux, sur lesquels le nombre d'unités à comparer est
inférieur.'' (p.32-33, notre traduction). Une prédiction de ce
modèle est que, dans la comparaison des suites de lettres, le
niveau de traitement le plus bas pourrait quand même contrôler la
réponse pour les comparaisons négatives : dès que deux
traits physiques diffèrent, le sujet peut être assuré de la
réponse (négative). En fait, il a été vérifié expérimentalement
qu'il n'y a pas d'effet de lexicalité sur les temps de réaction
des réponses "différent''.
Dans nos expériences de classification de la première syllabe de
stimuli CVCV, les sujets sont dans une situation proche de la
tâche de comparaison. En effet, comme il y a peu de stimuli
différents (2 ou 4), on peut concevoir que les sujets sont
capables de les mémoriser tous, et, qu'à chaque essai, ils
effectuent des comparaisons entre l'item présenté et les
représentations mémorisées pour chaque item. Cependant, soit
parce que les stimuli sont trop complexes acoustiquement, soit
parce que les sujets ne peuvent en mémoriser tous les détails, la
comparaison serait plus efficace à un niveau plus abstrait (i.e.
où il y a moins d'unités à comparer) qu'à un niveau purement
acoustique. Dans nos expériences, ce serait au niveau où le
stimulus ne forme qu'une unité (bisyllabique) que la comparaison
serait la plus efficace, et ce niveau contrôlerait la
réponse. Le modèle
de Forster permet donc de concilier nos résultats avec
l'hypothèse que le système perceptif récupère les phonèmes ou les
syllabes avant le stimulus "global''. Si ce modèle est
correct, il prédit un ralentissement dans tous les blocs
contenant quatre stimuli par rapport aux blocs contenant deux
stimuli, et suggère que la tâche à la Garner ne permet pas de
contraindre fortement les modèles de traitement de la
parole.
Il nous semble, cependant, que le paradigme de base peut être amélioré. Intuitivement, l'attention peut être focalisée sur un objet plus efficacement dans certains contextes plutôt que dans d'autres. Cela devrait se traduire par des coûts de variations différents selon les types d'interférences : certaines variations devraient coûter plus que d'autres à la prise décision. C'est cette intuition qui nous a conduit à réaliser l'expérience qui suit : si les phonèmes appartenant à la même syllabe sont "liés'' entre-eux, il doit être plus difficile de focaliser son attention sur un phonème quand il y a une variation à l'intérieur de la syllabe qui le contient plutôt qu'à l'extérieur de celle-ci.
La classification d'une voyelle est-elle affectée différemment quand on fait varier une consonne (a) dans la même syllabe et (b) dans une autre syllabe ? Dans cette expérience, les sujets doivent classifier soit la première, soit la seconde voyelle de stimuli VCCV. Ceux-ci peuvent appartenir à l'une des deux structures VC-CV (p.ex. /ac-ti/) ou V-CCV (p.ex. /a-cli/).
Notre manipulation consiste à faire varier ou non la première consonne du groupe CC central. Si les phonèmes appartenant à la même syllabe sont plus étroitement "liés '' que des phonèmes appartenant à des syllabes différentes, alors on s'attend à ce que la variation intra-syllabique gêne plus les sujets que la variation extra-syllabique ; autrement dit, l'interférence devrait être maximale pour classer V1 dans la structure V1C-CV2, et V2 dans la structure V1-CCV2.
Tous les stimuli avaient le format VCCV. La classification
portait soit sur la première, soit sur la seconde voyelle. On a choisi
/a/ et /u/ comme voyelles à classifier. La variation à ignorer
était localisée dans la première consonne, qui pouvait être, soit
le coda de la première syllabe (structure VC-CV), soit l'attaque
de la seconde syllabe (structure V-CCV). Le choix s'est
porté sur les plosives /k/ et /p/ car elles peuvent apparaître
aussi bien en coda de syllabe (kt/pt) qu'en début de groupe
commençant une syllabe (kl/pl). Le matériel est décrit dans la
table 2.4.
| icla/iclu |
|
|
| ipla/iplu |
On a construit 8 listes contrôles et 4 listes expérimentales. Dans les listes contrôles, seule la voyelle variait ; ces listes étaient donc formées à partir de deux items (par exemple: acti/ucti). Dans les listes expérimentales, la consonne variait également (p ou c); ces listes étaient donc formées à partir de 4 items (acti/ucti/apti/upti). Toutes les listes possédaient 64 essais dans un ordre aléatoire. En résumé, il y avait :
La procédure était identique à celle de l'expérience précédente.
Il y avait deux groupes de sujets : ceux qui classifiaient la première voyelle et ceux qui classifiaient la seconde voyelle. Pour chaque groupe, il y a quatre blocs contrôles et deux expérimentaux. Pour limiter le nombre de blocs à quatre par sujet, chacun n'a effectué que deux blocs contrôles. Pour contre-balancer l'ordre de chaque bloc, on a eu recours au dessin décrit dans la table 2.5.
| Sujet | 4|c|Séquence | |||
| 1 | E1 | C1 | E2 | P2 |
| 2 | C1 | E1 | P2 | E2 |
| 3 | E2 | P2 | E1 | C1 |
| 4 | P2 | E2 | C1 | E1 |
| 5 | E1 | P1 | E2 | C2 |
| 6 | P1 | E1 | C2 | E2 |
| 7 | E2 | C2 | E1 | P1 |
| 8 | C2 | E2 | P1 | E1 |
E=expérimental ; C=contrôle /c/ ; P=contrôle /p/ ; 1=VC-CV ; 2=V-CCV. Par exemple : P2=(apli/upli), E1=(acti/upti/apti/upti).
Seize étudiants, d'âges compris entre 20 et 25 ans, ont participé à cette expérience, pour laquelle ils recevaient 20 FF.
On a calculé les temps moyens et taux d'erreurs de chaque sujet dans chaque bloc, après avoir supprimé les huit premiers essais. La figure 2.3 présente les coûts de variation obtenus en soustrayant les temps de réaction des conditions contrôles à ceux des conditions expérimentales. La table 2.6 fournit les moyennes détaillées.
![\begin{figure}
\includegraphics [width=9cm]{actu.eps}
\end{figure}](img8.gif) |
Deux ANOVAs ont été effectuées : l'une sur les temps de réaction et l'autre sur les erreurs. Trois facteurs étaient définis : (a) Voyelle correspondant à la voyelle classée : V1 ou V2 (inter-sujets) ; (b) Structure : VC-CV ou V-CCV (intra-sujet) ; (c) Expérimental correspondant au type de bloc (Expérimental ou Contrôle) (intra-sujet).
Le facteur Expérimental produit un effet significatif : les sujets
sont 19 msec plus lents dans les blocs expérimentaux que dans les
blocs contrôles. L'effet de Voyelle est massif : les sujets qui
classifient V2 sont 120 msec plus rapides que ceux qui
classifient V1. Enfin, il y a une triple interaction
significative Voyelle ![]() Structure
Structure ![]() Expérimental ;
celle-ci signifie que, pour les coûts de la variabilité (égaux
aux différences "expérimental - contrôle''), il y a une
interaction entre Voyelle et Structure syllabique : les coûts
sont plus importants quand la voyelle à classer se trouve dans la
syllabe où la consonne varie. Les analyses restreintes à chaque
groupe de sujets montrent que ceux qui classifiaient la première
voyelle étaient gênés quand la consonne qui variait était dans la
même syllabe (structure VC-CV), mais pas quand elle était dans
la deuxième syllabe (V-CCV). À l'inverse, pour les sujets qui
classifiaient la seconde voyelle, l'effet de la variation
consonantique n'est pas significatif pour la structure VC-CV,
mais il est marginal pour la structure V-CCV. Dans l'analyse des
erreurs, la seule contribution significative provient d'une
interaction Voyelle
Expérimental ;
celle-ci signifie que, pour les coûts de la variabilité (égaux
aux différences "expérimental - contrôle''), il y a une
interaction entre Voyelle et Structure syllabique : les coûts
sont plus importants quand la voyelle à classer se trouve dans la
syllabe où la consonne varie. Les analyses restreintes à chaque
groupe de sujets montrent que ceux qui classifiaient la première
voyelle étaient gênés quand la consonne qui variait était dans la
même syllabe (structure VC-CV), mais pas quand elle était dans
la deuxième syllabe (V-CCV). À l'inverse, pour les sujets qui
classifiaient la seconde voyelle, l'effet de la variation
consonantique n'est pas significatif pour la structure VC-CV,
mais il est marginal pour la structure V-CCV. Dans l'analyse des
erreurs, la seule contribution significative provient d'une
interaction Voyelle ![]() Structure due au fait que les sujets
classifiant la seconde voyelle font relativement plus d'erreurs
quand la variation de la consonne est dans la seconde syllabe.
Structure due au fait que les sujets
classifiant la seconde voyelle font relativement plus d'erreurs
quand la variation de la consonne est dans la seconde syllabe.
PLAN S8<V2>*S2*T2\par V = Voyelle class\'ee (V1 ou V2) S = Structure : S1 = VC.CV ; S2 = V.CCV X = Type de bloc (Exp\'erimental vs controle) \par temps de r\'eaction X F(1,14)= 9.84 MSE=562.322 p=0.0073 S F(1,14)= 1.94 MSE=1373.14 p=0.1854 S.X F(1,14)= 0.84 MSE=439.624 p=0.3749 V F(1,14)= 15.37 MSE=15016.3 p=0.0015 V.X F(1,14)= 3.78 MSE=562.322 p=0.0722 V.S F(1,14)= 2.15 MSE=1373.14 p=0.1647 V.S.X F(1,14)= 7.06 MSE=439.624 p=0.0188 X/V1/S1 F(1,7)= 8.51 MSE=1121.59 p=0.0224 X/V1/S2 F(1,7)= 2.14 MSE=242.297 p=0.1869 X/V2/S1 F(1,7)= 0.05 MSE=358.973 p=0.1706 X/V2/S2 F(1,7)= 3.74 MSE=281.036 p=0.0944 \par Erreurs : X F(1,14)= 0.20 MSE=1.2634 p=0.3384 S F(1,14)= 2.90 MSE=1.7455 p=0.1107 S.X F(1,14)= 0.25 MSE=2.2634 p=0.3752 V F(1,14)= 3.04 MSE=3.4777 p=0.1031 V.X F(1,14)= 1.24 MSE=1.2634 p=0.2842 V.S F(1,14)= 5.16 MSE=1.7455 p=0.0394 V.S.X F(1,14)= 0.11 MSE=2.2634 p=0.2549 X/V1/S1 F(1,7)= 1.00 MSE=1 p=0.3506 X/V1/S2 F(1,7)= 0.80 MSE=0.7054 p=0.4008 X/V2/S1 F(1,7)= 0.13 MSE=0.4911 p=0.2709 X/V2/S2 F(1,7)= 0.21 MSE=4.8571 p=0.3393
Le résultat principal de cette expérience est attesté par la triple interaction : les sujets sont plus gênés pour classifier une voyelle si l'on fait varier une consonne qui se trouve dans la même syllabe plutôt qu'une consonne qui se trouve dans une autre syllabe. L'interférence est relativement moins importante pour les sujets qui classifient la seconde syllabe que pour ceux qui classifient la première. Cela pourrait être dû à la distance en nombre de phonèmes entre le lieu de variation et le lieu de classification (2 phonèmes quand on classifie V2 contre 1 phonème quand on classifie V1). On peut également remarquer que V2 est traitée nettement plus rapidement que V1. Cela peut provenir de nombreux facteurs dont les plus plausibles sont : (a) un effet de baisse du critère de décision quand on progresse à l'intérieur des stimuli [LuceLuce1986] ; (b) la présence d'indices acoustiques sur l'identité de la seconde voyelle, dus à une coarticulation anticipatrice, et présents avant le début de la périodicité vocalique (à partir duquel est mesuré le temps de réaction).
On ne peut pas rendre compte des interférences observées en
supposant simplement que les sujets effectuent une comparaison
globale des stimuli. Pour les expliquer, il faut faire référence
à la composition interne des stimuli : dans les blocs
expérimentaux avec variation "intra-syllabique'', quatre
syllabes pouvaient apparaître dans la position examinée par les
sujets (p.ex. AC-ti, AP-ti, UC-ti, UP-ti) ; dans les blocs "
extra-syllabiques'', il n'y en avait que deux (p.ex A-cli,
A-pli, U-cli, U-pli). On pourrait envisager que les sujets
répondent en utilisant exclusivement la syllabe qui contient le
phonème, mais cela n'explique pas pourquoi l'interférence paraît
plus faible en seconde syllabe qu'en première, et surtout, cette hypothèse est démentie
par les expériences précédentes : celles-ci montraient que
l'attention ne peut pas être focalisée parfaitement sur une
syllabe. Dans le cadre du modèle de Forster, le niveau syllabique
serait donc un niveau parmi d'autres qui influencent la réponse.
Cependant, c'est un niveau qui semble calculé
automatiquement, puisqu'il influence les sujets dans une tâche
qui ne requiert pas explicitement la manipulation de syllabe
(exp.3). En cela, notre résultat est à rapprocher de l'effet de
complexité syllabique en détection de phonème initial
[Segui, Dupoux MehlerSegui
1990] : dans les deux cas, les sujets doivent effectuer
une tâche sur des phonèmes et s'avèrent sensibles à la
structure de la syllabe qui les contient.
Dans le paradigme de Garner, le sujet doit
classifier des objets (p.ex. des syllabes CV) selon une dimension
(p.ex. l'identité du premier phonème : la consonne C). Dans
certains blocs d'essais, une seconde dimension (p.ex. la voyelle
V) varie, alors que dans d'autres blocs, elle ne varie pas. Si
les sujets sont ralentis par la variabilité de la seconde
dimension, ou, en d'autres termes, s'ils sont incapables de
focaliser leur attention sur la dimension à classifier, alors on
considère généralement que cela est la preuve d'un traitement
perceptif holistique des stimuli
[GarnerGarner1974]. Ainsi, le fait que les sujets soient gênés pour
classifier une consonne quand la voyelle varie semblait un
argument en faveur de la syllabe en tant qu'unité de perception
[Wood DayWood Day1975]. Un tel raisonnement prédit que les sujets
doivent pouvoir classifier une syllabe sans être dérangés par la
variation d'une syllabe adjacente. En fait, l'expérience
2.1 montre que les sujets ne peuvent pas ignorer la
variation de la seconde syllabe quand ils doivent classifier la
première syllabe de stimuli CV-CV. L'expérience
2.2 montre que cela n'est pas dû à un effet de
coarticulation entre la seconde et la première syllabe, et montre
au passage que les sujet ne peuvent se focaliser sur l'acoustique
du signal pour effectuer la
tâche.
Notre interprétation favorise une explication décisionnelle des effets d'interférence : les sujets ne peuvent s'empêcher d'être distraits par la variation (cf discussion de l'expérience 2.2). Si l'on réalisait ce type d'expérience dans la modalité visuelle (en présentant sur un écran "PA'', "TO''...), il est probable que la variation gênerait également les sujets, bien qu'il existe des invariants de forme qui caractérisent la première lettre. Apparemment, les sujets ne sont pas capables de focaliser leur attention sur une lettre, un phonème ou une syllabe. Cela ne prouve pas que ces objets ne sont pas des unités de traitement utilisées par le système perceptif.
Une alternative à l'explication en terme de distraction, est que
les sujets utiliseraient spontanément une stratégie holistique
(i.e. considèreraient le stimulus global) pour répondre : dans
les blocs contrôles, il y a deux objets à discriminer, dans les
blocs expérimentaux, il y en a quatre, ce qui expliquerait la
différence de temps de réaction. Les deux types d'explication
suggèrent que la découverte d'une différence de temps de réaction
moyens entre des blocs contenant quatre stimuli et des blocs
en contenant deux ne permet pas de conclure, ni sur le traitement
ni sur la représentation utilisée par les sujets pour
répondre. Cependant,
l'explication en terme de distraction soulève la possibilité que
différents types de variations puissent produire des
interférences plus ou moins grandes. C'est cette idée qui a
présidé à la réalisation de l'expérience
2.3.
Si les sujets qui classifient des phonèmes utilisent une représentation qui est une simple concaténation de phonèmes, alors on s'attend à ce que l'interférence due à une variation soit indépendante de la structure syllabique des stimuli. Si, au contraire, cette représentation est structurée syllabiquement, c'est à dire, si les phonèmes appartenant à la même syllabe sont plus "liés'' que les phonèmes appartenant à des syllabes différentes, alors on s'attend à ce que les variations intra-syllabiques "coûtent'' plus que les variations extra-syllabiques. Dans l'expérience 2.3, les sujets devaient classifier une voyelle quand variait une consonne qui se trouvait, soit dans la même syllabe, soit dans une autre syllabe, que la voyelle à classer : l'interférence était maximale quand la variation était à l'intérieur de la syllabe.
Il faut conclure que les phonèmes appartenant à la même syllabe sont plus "liés'' que des phonèmes appartenant à des syllabes différentes. Ce résultat est important, car il montre la sensibilité des sujets à la structure syllabique dans une tâche qui ne requiert pas la manipulation explicite de syllabes, mais il faut souligner qu'il ne permet pas de déduire qui, de la syllabe, ou du phonème est récupéré en premier par le système perceptif. Pour des raisons inhérentes à la tâche, le système de décision pourrait accéder préférentiellement à une représentation syllabifiée du signal, bien que celle-ci ne soit pas la première extraite du signal. D'ailleurs, en employant un paradigme expérimental très différent de celui de Garner, Pitt et Samuel (1990) ont affirmé que les sujets pouvaient focaliser leur attention précisement sur un phonème, et ont conclu que celui-ci, plutôt que la syllabe, était l'unité de perception. Dans le chapitre suivant, nous allons examiner en détail leur proposition.